7 分钟
Spark 笔记
一、安装配置
1、前提条件
- JDK 1.8
- Hadoop 集群方式安装
- Scala 2.11.x
(1)安装Scala
下载scala,并安装
su
wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz
tar zxvf scala-2.11.12.tgz
mkdir /usr/scala
mv scala-2.11.12 /usr/scala/
cd /usr/scala/
ln -s /usr/scala/scala-2.11.12 default
vim /etc/profile
# Scala
export SCALA_HOME=/usr/scala/default
export PATH="$SCALA_HOME/bin:$PATH"2、安装
http://spark.apache.org/downloads.html
选择下载没有hadoop包的版本
(1)下载解压
# 重要:su 到hadoop运行的用户
wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-without-hadoop.tgz
sudo mkdir /usr/spark
sudo chown xxx:xxx /usr/spark
tar zxvf spark-2.4.0-bin-without-hadoop.tgz
mv spark-2.4.0-bin-without-hadoop /usr/spark/
cd /usr/spark/
ln -s /usr/spark/spark-2.4.0-bin-without-hadoop default
cd default/conf(2)配置
环境变量sudo vim /etc/profile
# Spark
export SPARK_HOME=/home/spark/default
export PATH=$SPARK_HOME/bin:$PATH编辑Spark环境cp spark-env.sh.template spark-env.sh && vim spark-env.sh
# 由于ssh执行脚本环境变量会失效,所以需要在此重新加载环境变量
export PATH=/usr/local/bin:/usr/bin
source /etc/profile
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export JAVA_HOME=/usr/java/default #Java环境变量
export SCALA_HOME=/usr/scala/default #SCALA环境变量
export SPARK_WORKING_MEMORY=512m #每一个worker节点上可用的最大内存
export SPARK_MASTER_HOST=hadoop-master #master节点主机名
SPARK_MASTER_PORT=7077 # master 通信端口,worker和master通信端口
SPARK_MASTER_WEBUI_PORT=8080 # master SParkUI用的端口
export HADOOP_HOME=/usr/hadoop/default #Hadoop路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #Hadoop配置目录
export SPARK_WORKER_CORES=1 #每个节点多少核
export SPARK_WORKER_INSTANCES=1 #每台机器上开启的worker节点的数目编辑集群情况cp slaves.template slaves && vim slaves
hadoop-slave1
hadoop-slave2验证
spark-shell(3)分发到slave节点
使用scp工具
(4)启动关闭spark
sbin/start-all.sh
sbin/stop-all.sh(5)验证
在各个节点输入jps命令。可以看到Master或者Worker输出
访问Master节点8080端口http://192.168.3.20:8080/
将看到两个worker
二、模型与机制
1、术语定义
用户程序相关
- Application 指用户编写的程序,包含Driver和Executor
- Dirver 一般指Application上的Main函数创建的SparkContext, SparkContext是:
- Spark应用程序的运行环境
- 负责与ClusterManager通讯,申请资源、任务的分配和监控
- Executor 指运行在Worker节点上的一个进程,负责运行Task,并负责将数据存储在内存或磁盘上,每个Executor并行Task的数目默认取决于CPU数
集群管理相关
- Cluster Manager 集群管理者
- standalone
- yarn
- Worker 工作机器守护进行,负责启动管理Executor
运行时相关
- Job 包含多个Task组成
- Stage Job被拆分为多组的Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段,阶段之间存在上下游关系
- Task 被送到某个Executor上的工作任务
2、执行过程
- 创建应用程序计算 RDD DAG(有向无环图)
- 创建RDD DAG逻辑执行方案,将计算过程应用到Stage
- 获取Executor来调度并执行各个Stage对应的ShuffleMapResult和ResultTask等任务,必须是一个Stage执行完成后下一个Stage才能执行
(1)Stage划分
划分Stage的方式是判断是算子之间是否产生宽依赖(宽依赖就是指父RDD的分区被多个子RDD的分区所依赖),Stage之间必然有Shuffle产生
(2)partition与并行度的划分
partition决定了Task的数目和每个分区文件的大小,partition越大,分区文件越小,Task数目越多,占用资源越高,额外开销越大,运行速度越快
三、参数与优化
1、自适应shuffle分区
参考 https://blog.csdn.net/u013332124/article/details/90677676
Adaptive Execution简称AE。原理是:
- 在Shuffle过程中设定最大分区数目和分区文件期望大小。
- 针对小分区,将对分区文件进行合并,使之达到期望文件大小的尺寸以减少task
开启方式
set spark.sql.adaptive.enabled=true;
set spark.sql.adaptive.join.enabled=true;最大并行度(也是初始并行度)(最大分区数目)
set spark.sql.adaptive.maxNumPostShufflePartitions = 300- 要保证
targetPostShuffleInputSize * maxNumPostShufflePartitions * 1.2 > 最大stage的shuffle read size否者会导致运行速度变慢(因为stage的分区太大)
Shuffle read从每个上游task拿到的文件尺寸的最大值
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize;执行过程
- 上游stage的每个task进行Shuffle Write,分区数为
spark.sql.adaptive.maxNumPostShufflePartitions - dirver 会汇总每个上游stage中每个task的Shuffle Write的每个分区的编号和文件大小,计算出下游任务数和每个任务读取每个上游任务的那几个partition
- 规则是,针对每个上游task从0号分区其获取连续的、总大小小于
spark.sql.adaptive.shuffle.targetPostShuffleInputSize的连续分区作为下游一个任务的输入 - 按照上述规则划分分区,最后得到的分区组的数目就是下游task的数目,每个分区需要读取的分区编号就是这个连续的范围
- 创建这些task
- 规则是,针对每个上游task从0号分区其获取连续的、总大小小于
- 下游task并行获取分区数据
2、Cache Table
四、Spark原理与实现
1、总体介绍
https://spark-internals.books.yourtion.com/markdown/1-Overview.html
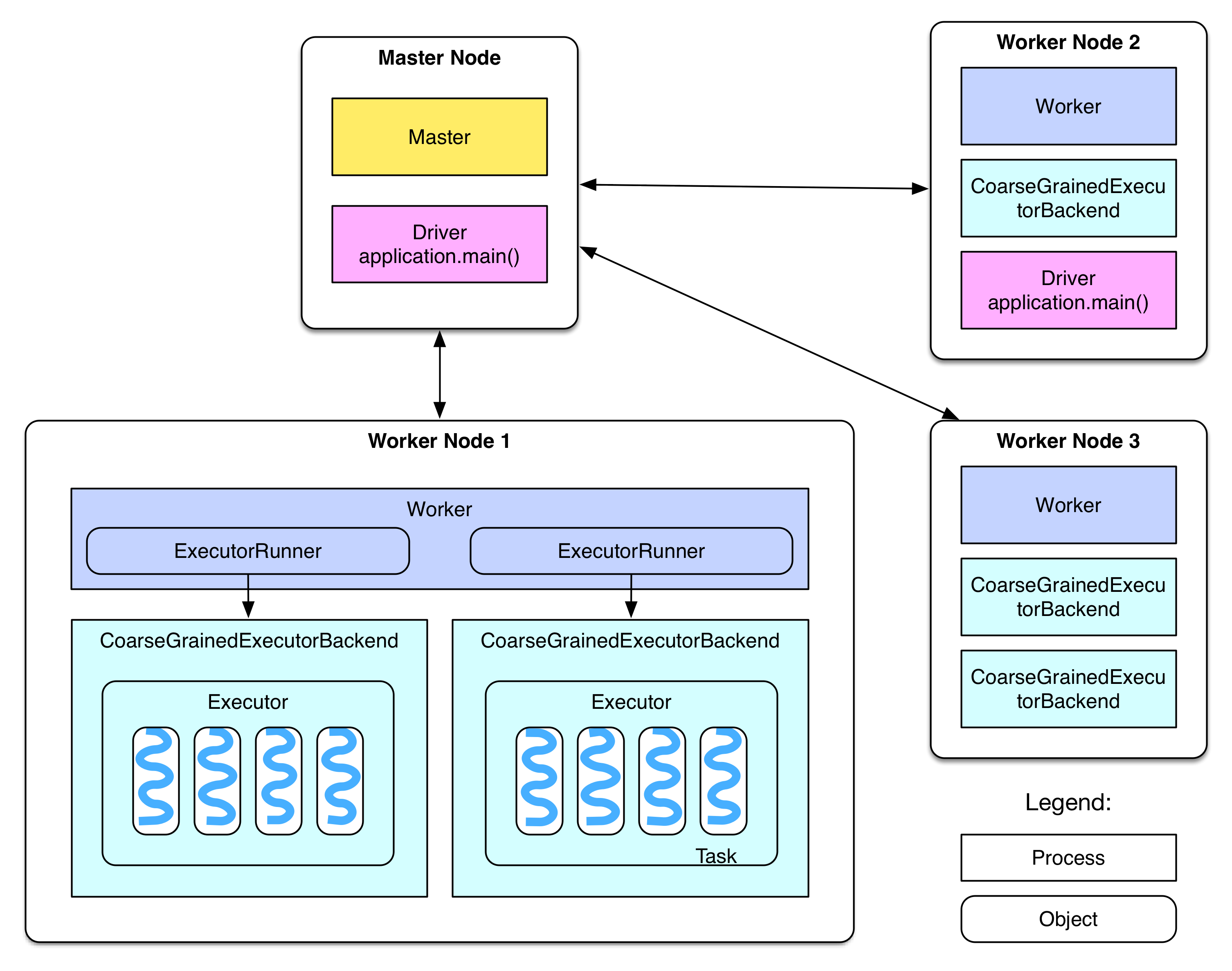
- 上图的 Master Node 的 Master 为 Master Domain Process (Master 守护进程),每个集群一个,生命周期和集群一致
- 上图的 Worker Node 存在 Worker Domain Process (Worker守护进程),每个集群多个,一般一台机器一个,生命周期和集群一致
- 上图的 Driver 可以运行在 Master Node 或者 Worker Node,和Application一一对应,生命周期和Application一致
- 上图的 Executor 存在于 每个Worker中,由 Worker Domain Process 创建,每个Worker可能存在多个
- 每个 Executor 存在一个线程池,线程池的数目受
spark.executor.cores参数影响 - 每个 Executor 的每个线程会运行一个 task,同一个 Executor 执行同一个任务
- 每个 Executor 存在一个线程池,线程池的数目受
其他参考文档
五、场景
1、MySQL binlog Dump
- 搭建 Canal 接入MySQLBinLog
- Canal 将数据发送到 Kafka
- Kafka 同步到 hdfs
- spark读取增量数据并做成虚表,进行merge
2、数据倾斜处理
六、疑问自答
1、什么是AE
全称 adaptive execution,有如下作用
- 根据配置的ShufflePartition文件大小,自动配置每个Stage的Partition数
- 每个Stage执行完成之后,根据统计信息动态改变物理执行计划,重新生成RDD代码
- 决定是否使用boardcast
- 打开AE,Spark History UI的Stage DAG图会出现很多跳过Stage
- 打开AE后,Spark History UI 的 SQL DAG图会随运行过程中不断变化
2、Spark Application、Driver、Job、Stage、Partition、Task及如何划分
Spark Application:
- 通过spark-submit提交的一个程序称之为Application
- 一个spark-shell称之为一个Application
Driver:
- 运行用户提交主代码的进程,负责
- 解析用户输入
- 构建执行图
- 调度协调Task
Job:
- 一个Application可以划分为1个或多个Job
- 划分Job的依据是:调用了action算子(ResultTask),action算子:
- 收集信息到Driver程序
- 一般情况下
- AE:一个SparkSQL的每个Stage就是一个Job(因为AE会动态调整执行计划,需要收集信息到Driver)
- 非AE:一个SparkSQL(insert into)一般对应一个一个Stage(因为物理执行图一旦确定就不会变,直到action操作insert into)
Stage:
- 一个Job包含一个或者多个Stage,以Shuffle为界
Partition
- Partition 是一个数据分片,完整的数据会分为多个Partition
Task
- 一个Stage会启动多个Task,这些Task封装了相同的计算流水线,只是处理的数据不同。
- 一个任务task的个数和Stage最后一个RDD的partition数目相同。(参考 不管是 1:1 还是 N:1 …)
- task执行会以流水线的方式向上追溯到读表或者ShuffleRead,然后依次处理
3、Random等不确定函数作为joinkey时的问题
当在使用Random函数作为joinkey处理数据倾斜问题时,在失败重试的情况会导致数据不一致。
Join下游Task某个shuffle fetch faild,就需要重跑上游Stage,此时Random函数式不确定函数,重跑导致前后数据不一致。从而造成数据不一致
解决办法: 使用其他确定字段代替random生成JoinKey
4、前缀优化
select
t1.a, t1.b,
count(1) as uv,
sum(vv) as vv
from
(
select
t1.a, t1.b, t1.c,
count(1) as vv
from t1
left join t2
on t1.a = t2.a
group by t1.a, t1.b, t1.c
) x
group by t1.a, t1.b以上SQL如果没有优化的话会产生3个Shuffle,分别是
- Shuffle1:
- t1 join t2
- shaffle key 为 t1.a
- Shuffle2:
- group by t1.a, t1.b, t1.c
- shaffle key 为 t1.a, t1.b, t1.c
- Shuffle3:
- group by t1.a, t1.b
- shaffle key 为 t1.a, t1.b
可以观察到,shuffle1 的 key 是 shuffle2 key 的前缀。所以 shuffle2 可以优化为窄依赖